




News
Evaluating the effects of non-representative sampling designs on species distribution models
Species distribution models are a powerful tool for investigating the main factors driving the selection and the avoidance of certain habitats and environmental features by species. Theoretically, distribution models should be produced by evenly sampling all the environmental conditions of the study area in which the focal species is being investigated, in order to provide as a detailed and precise description of the habitat gradients and of the species presence and absence as possible. However, optimally designed surveys are rare because they could be logistically difficult and expensive (e.g., when focal species are rare and cryptic, or when they occur in remote areas).
Therefore, surveys are often carried out optimistically where species are already expected to occur and in areas that are more accessible, in order to maximize the effort. However, this often results in surveys that are spatially biased. The effects of this spatial bias on the performances of presence-absence species distribution models have rarely been investigated, and here we assessed the effects of spatial bias on a distribution model for the flammulated owl (Psiloscops flammeolus) in the Northern Rocky Mountains.
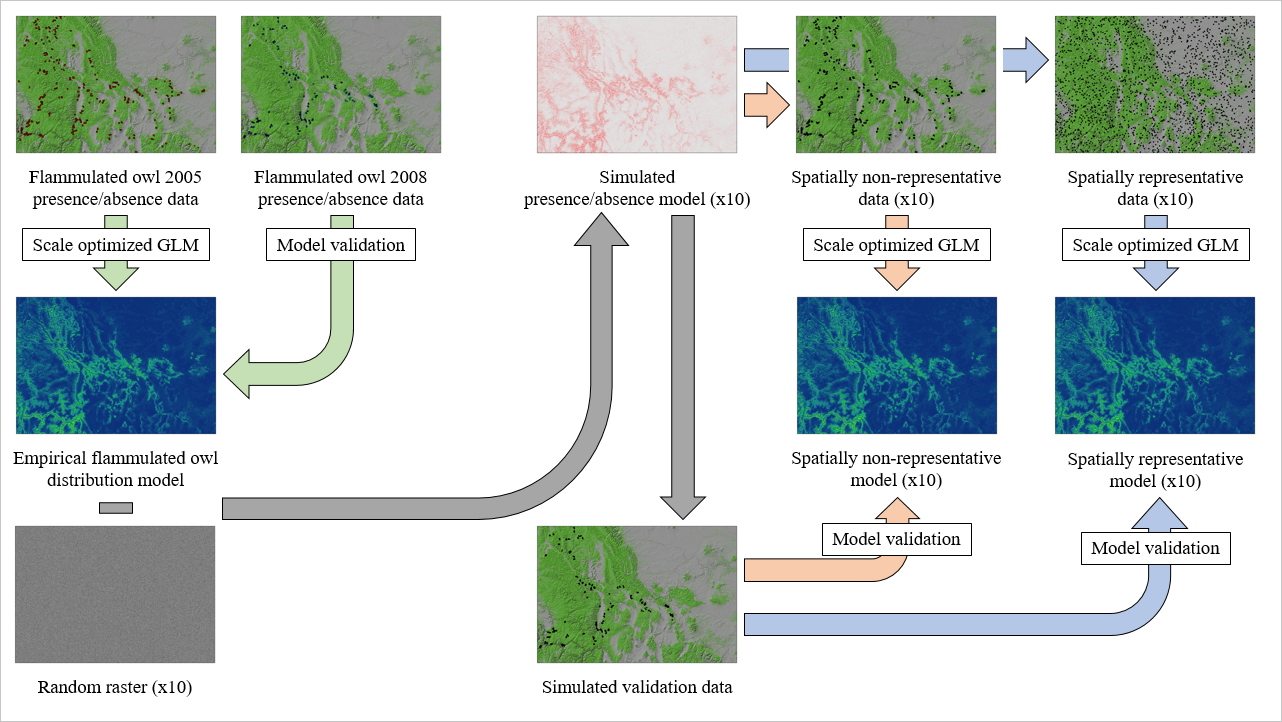
We first generated a species distribution model for the species, using presence-absence data gathered from a survey carried out in forested areas where the species was already known to occur, and following paths and trails – hence, spatially biased. Then, using simulations built on the empirical species distribution model, we created two simulated sets of data: a spatially biased one and a spatially unbiased one. Hence, we produced simulated species distribution models using the new data sets, and compared the results to the empirical model.
Our hypothesis was that models trained with spatially biased data sets would suffer from bias in parameter estimates, and would show lower predictive performance. Our results showed that the models trained with the spatially unbiased data sets greatly outperformed the models trained with the spatially biased simulated data sets judged on standard metrics of model performance. However, the spatially biased models produced superior predictions based on their ability to identify the correct spatial scales, covariates, signs and magnitudes of the species-environment relationships, when compared to the spatially unbiased models.
Thus, it is likely that representative spatial sampling across a broad range of environmental gradients also resulted in over-dispersion of sampling data, with a higher proportion of samples falling in areas of low probability of presence, leading to lower ability to resolve the relationships between species presence-absence and environmental covariates.
In contrast, the spatially biased sampling, by concentrating sampling along environmental gradients that are characterized by higher probability of presence of the focal species, produced predictions that, while seeming to be weaker based on standard measures of model performance, greatly outperformed the spatially unbiased models based on measures of true model prediction (e.g., correctly describing the actual spatial scales, direction and strength of species-environment relationships).
Chiaverini, L., Wan, H.Y., Hahn, B., Cilimburg, A., Wasserman, T.N. and Cushman, S.A., 2021. Effects of non-representative sampling design on multi-scale habitat models: flammulated owls in the Rocky Mountains. Ecological Modelling, 450, p.109566.
